从数据中心出发,寻找下一个闪迪(一)
作者:人工智能胡思乱想 日期:2026年5月5日 22:01 来源:https://mp.weixin.qq.com/s/LBg_YmR4ZGvNPZsZ4Q11xw
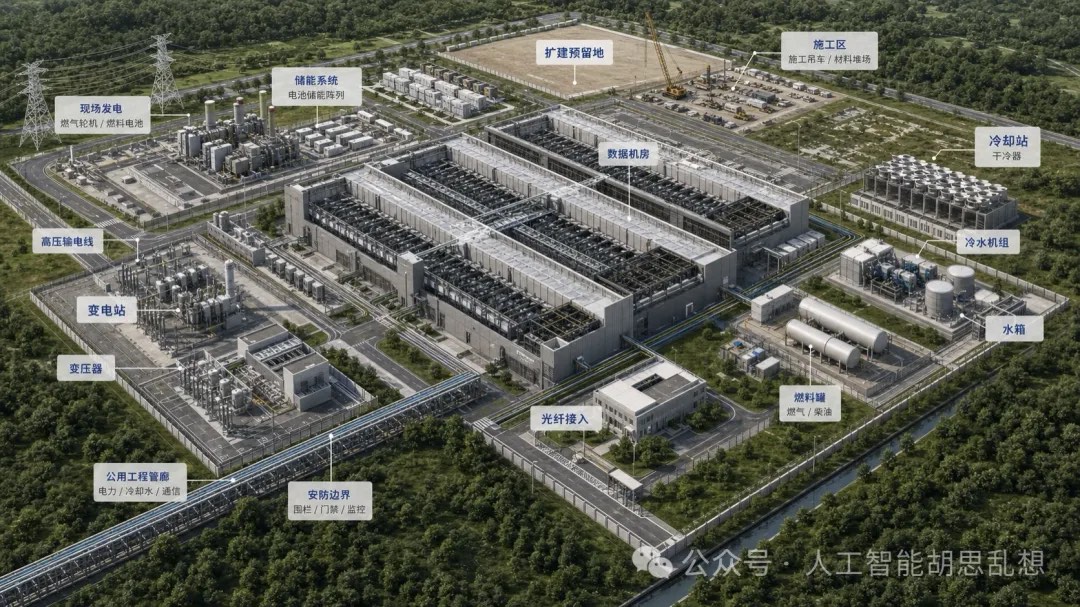
引言
AI 数据中心的投资线索已经从单一 GPU 供给转向完整基础设施系统。训练阶段的核心约束是 GPU、HBM 与先进封装;推理阶段的约束会扩散到电力、供配电、冷却、网络、存储、带电土地和设施交付。本文将 AI 数据中心开始,尝试从下一个技术周期的供需极点入手,寻找 “下一个闪迪”。我们尝试将数据中心拆解为十层:计算、内存与存储、网络与互联、发电、电力输配、冷却、先进封装与基板、土地与建设、能源基础设施、设施系统。十层之间高度耦合。任一关键层交付延迟,都会推迟整座数据中心上线。
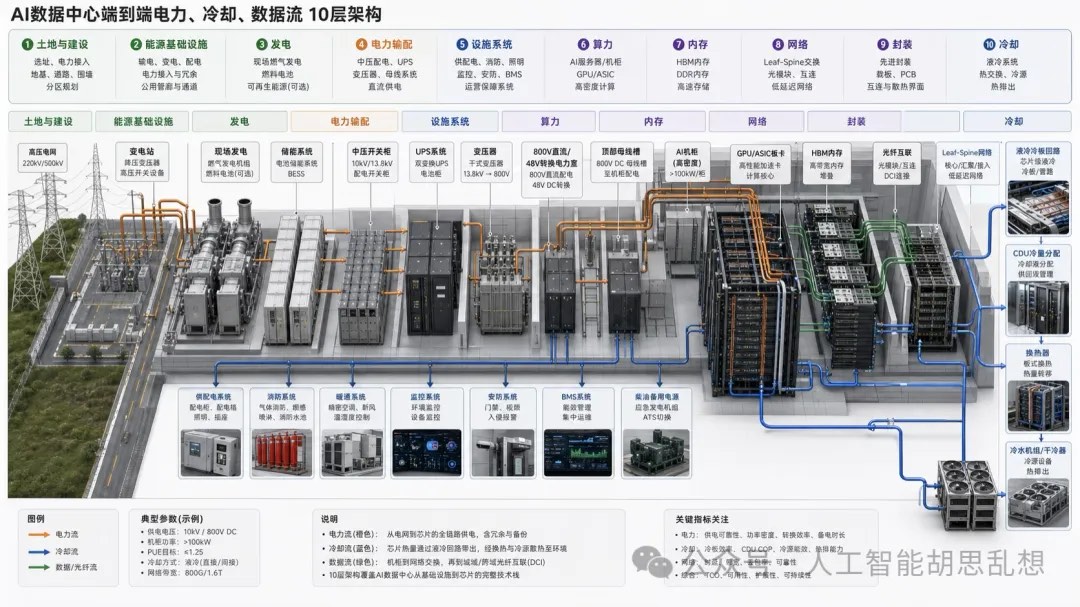
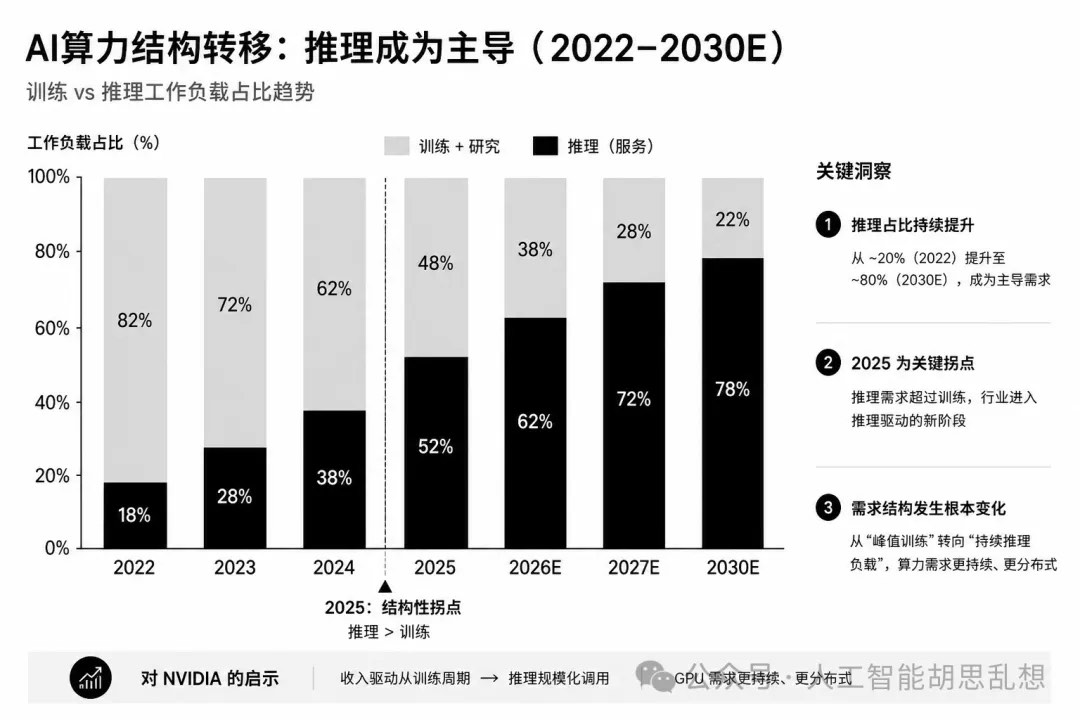
推理时代改变了数据中心的供需关系。AI 负载从集中训练转向分布式推理,从文本问答转向多模态生成,从单次响应转向 Agent 长链路任务。结果是 GPU 仍然重要,但 CPU、SSD、光互连、液冷、电力设备和能源基础设施的边际价值上升。

第一层:计算
计算层决定 AI 数据中心的有效算力供给。训练侧仍由 GPU 主导,推理侧正在形成 GPU、ASIC、CPU 并存的结构。
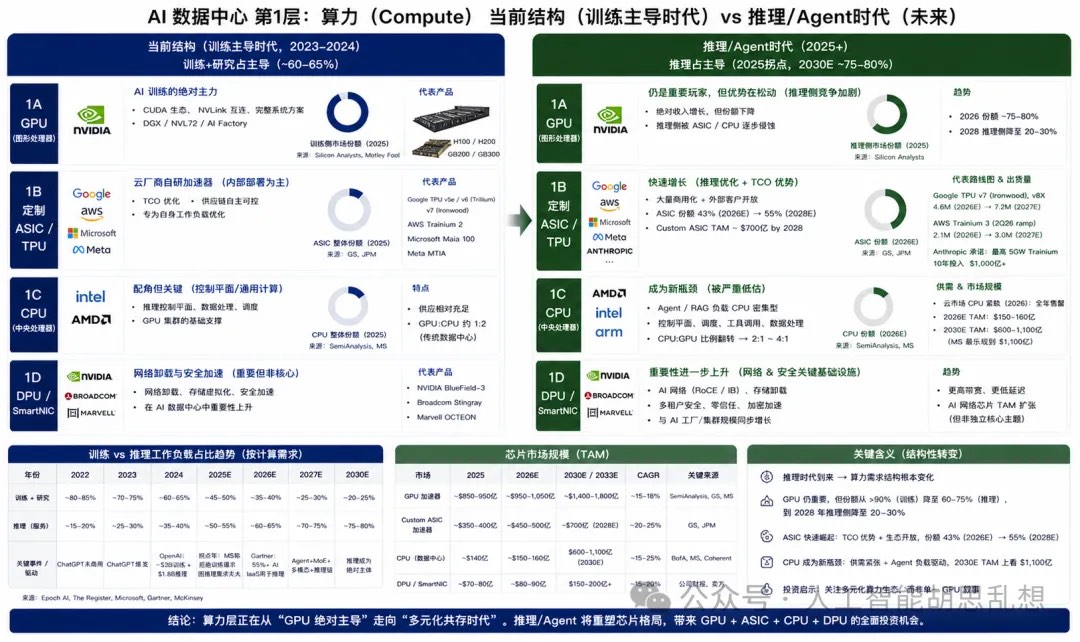
GPU 仍是训练核心资产
GPU 是训练任务的主力。NVIDIA 凭借 CUDA、NVLink、InfiniBand、DGX/NVL 系统方案建立高进入壁垒。训练侧的替代成本仍高,份额和生态优势短期难以被快速复制。推理阶段的竞争结构更分散。推理任务更重视单位成本、能耗、延迟和部署弹性。ASIC、CPU 和部分边缘芯片会在稳定、大规模、成本敏感的场景中获得份额。
定制 ASIC 是超大规模云厂商的成本工具
Google TPU、Amazon Trainium、Microsoft Maia 和自研 Arm CPU 代表云厂商的垂直整合方向。核心目标不是替代所有 GPU,而是在高重复、高规模、高成本敏感的推理负载中降低 TCO。Google TPU 正从内部算力工具转向更开放的外部服务能力。Amazon Trainium 已成为 Anthropic 等大客户的重要算力承诺基础。Broadcom 是定制 ASIC 生态中最重要的外部设计与互连合作方之一,受益于 XPU 客户数量增加和客户集中度改善。
CPU 是推理和 Agent 的控制面瓶颈
CPU 在训练时代被低估,在推理时代重新成为基础设施约束。Agent 调度、工具调用、RAG 检索、数据库查询、上下文管理、请求编排和后处理主要由 CPU 承担。GPU:CPU 配比会随负载结构变化。传统数据中心更接近 GPU:CPU 约 1:0.5;Agent 型负载可能上升至 1:2 甚至 1:4。每颗 GPU 需要更多 CPU 处理控制面和数据面任务。
投资含义。 NVIDIA 仍是训练侧核心资产,但估值已反映大量 AI 预期。边际变化来自 CPU、ASIC 和系统级互连。AMD、Intel、Broadcom 和 Arm 的投资价值取决于推理负载占比、云厂商自研芯片商业化、服务器 CPU 供需和系统级设计份额。
公司角色投资变量NVIDIA GPU 与系统平台高端训练与推理 GPU 需求、Rubin/Feynman 代际切换、系统级毛利AMD CPU 与 GPU EPYC 份额、MI 系列放量、GPU 与 CPU 绑定销售能力Broadco 定制 ASIC 与网络芯 XPU 客户数、AI 网络芯片、光 DSP 与 retimer m 片Intel 服务器 CPU 与封装 CPU 需求复苏、先进封装、制程与交付验证
Arm IP 与架构云端 Arm CPU 渗透率、授权费率和客户扩张
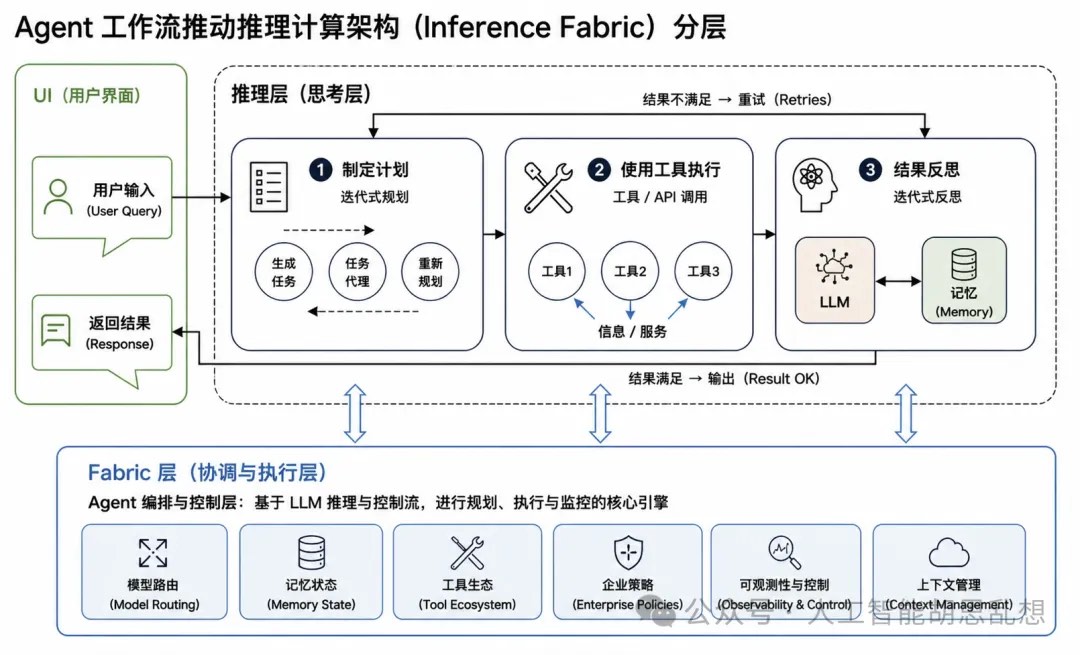
第二层:内存与存储
推理时代把存储从“数据仓库”升级为“AI 记忆系统”。训练时代主要关注 HBM;推理时代需要 HBM、DDR、SSD、机架级闪存阵列和分布式存储共同管理 KV 缓存、上下文和长期记忆。
推理时代内存层级(英伟达 2026 CES)
层级资产功能投资含义G1 HBM 承载最热的 token 计算高性能训练和推理仍依赖 HBM G2 DDR 承载近端上下文和缓存推理控制面提高 DRAM 需求G3 本地 SSD 承载会话历史和热数据回放数据中心 SSD 需求上升G3.5 机架级闪存阵列承载共享上下文和长期记忆 CXL、NVMe、存储网络价值上升G4 分布式存储承载训练数据和冷归档企业存储厂商进入 AI 基础设施链HBM 供给仍紧,但更重要的变化来自 NAND 和 SSD。DRAM 厂商扩产 HBM 会挤占部分 NAND 资源,推理侧又增加高性能 SSD 需求。供给收缩和需求扩张同时出现时,SSD 具备类似历史 NAND 周期的重估条件。CXL 是新的连接层。它允许服务器把内存池化和扩展,缓解 HBM 成本压力。Astera Labs 等公司受益于 CXL 控制器、retimer 和内存扩展生态形成。投资含义。存储层的机会不止 HBM。推理时代更值得跟踪的资产包括数据中心 SSD、CXL 连接芯片、机架级闪存阵列和企业级 AI 存储系统。SanDisk 的启示在于:当普通 NAND/SSD 变成 AI 记忆基础设施,估值框架会从周期品转向瓶颈资产。
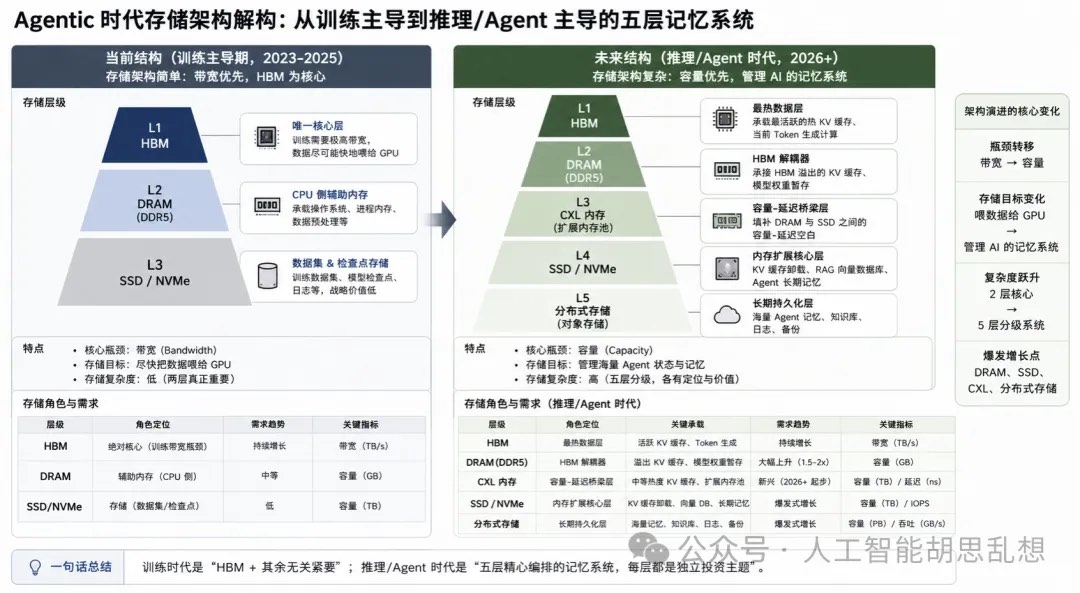
第三层:网络与互连
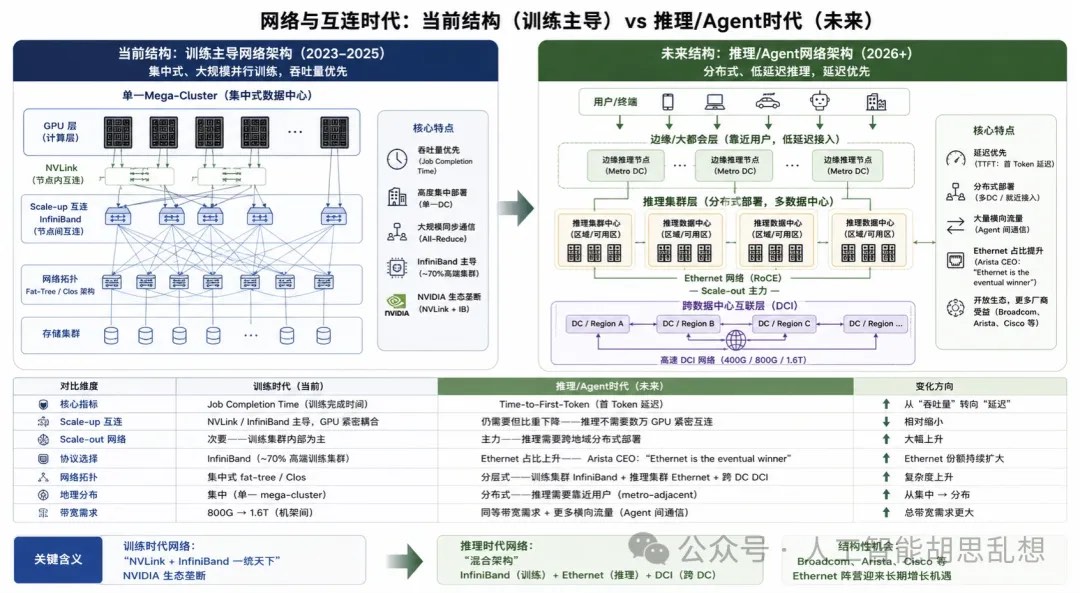
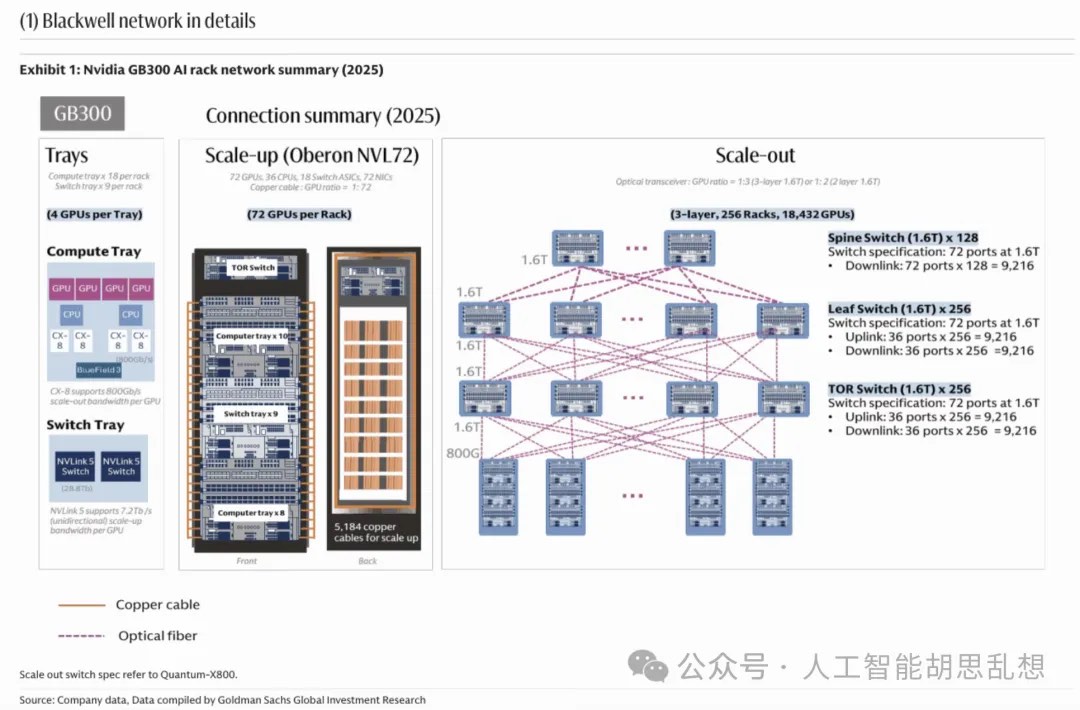
网络层决定算力能否被有效组织。训练阶段强调低延迟、高吞吐的单集群协同;推理阶段强调跨区域部署、低首 token 延迟、开放 Ethernet 和更复杂的数据中心互连。
训练网络:封闭、高带宽、集中式
训练网络的目标是缩短训练完成时间。Scale-up 连接通过 NVLink 把同一机架内 GPU 作为一个紧密系统;Scale-out 连接通过 InfiniBand 或高端 Ethernet 扩展到更大集群。
推理网络:开放、分布式、低延迟
推理网络的目标是降低首 token 延迟并提高覆盖范围。用户请求分布在全球,数据中心需要更接近用户,metro-adjacent 站点增加,跨数据中心 DCI 和东西向流量上升。
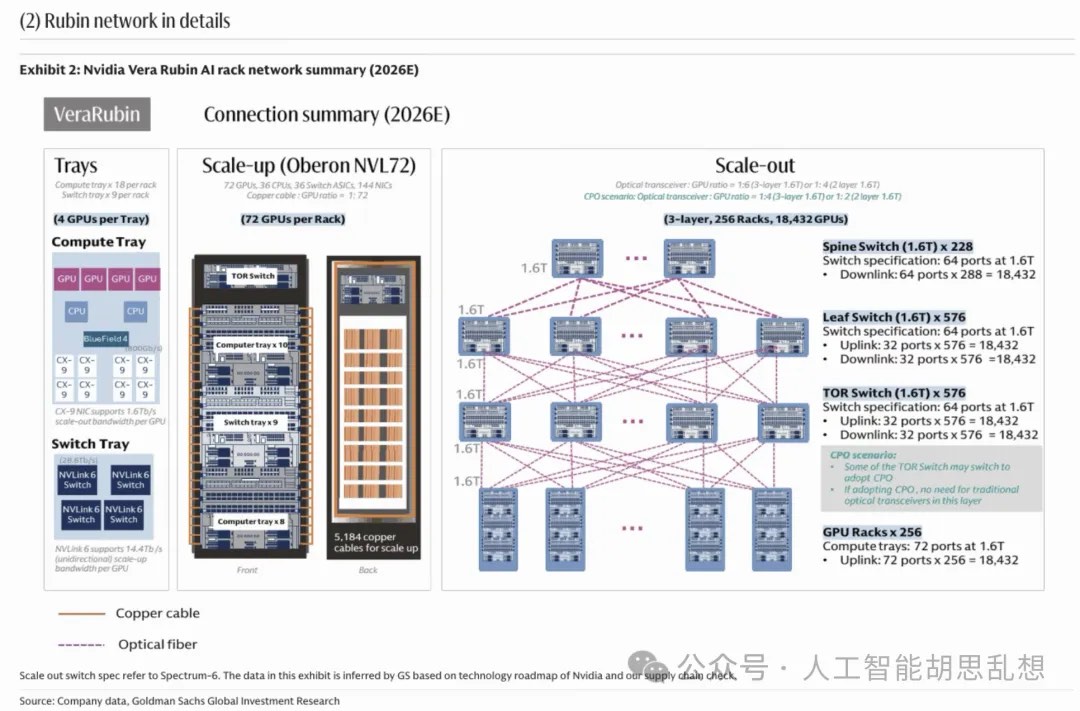
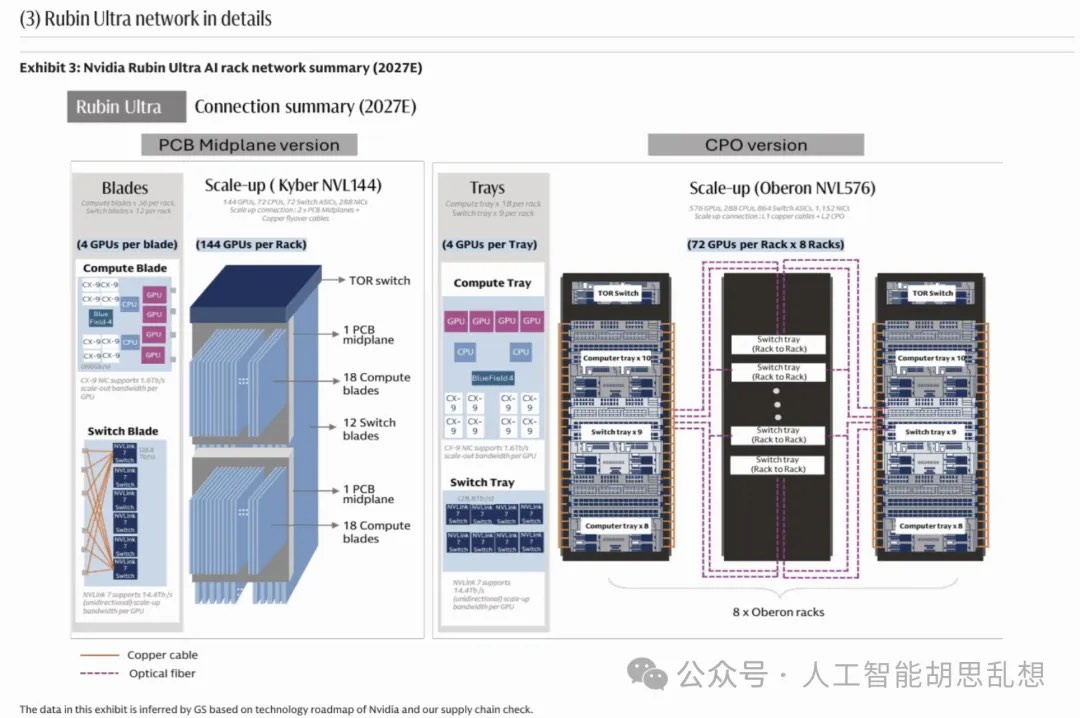
互连方式演进
铜互连和光互连不是替代关系。机架内短距连接继续使用 DAC、ACC、AEC 和 retimer;机架间连接升级到 800G、1.6T 和 3.2T 光模块;跨数据中心连接依赖 coherent optics 和 DCI。CPO 是长期方向,但短期节奏需要区分。共封装光学能降低功耗和提高密度,但大规模采用需要交换芯片、封装、激光器、维修模式和供应链共同成熟。2026-2028 年,传统可插拔光模块、AEC、光 DSP 和 retimer 仍是主要投资载体。
投资含义。网络层从封闭生态走向开放生态。Broadcom、Marvell、Credo、Arista、Ciena 和光模块龙头分别卡位交换芯片、DSP、AEC、系统交换机、DCI 和可插拔光模块。Credo 的弹性来自铜互连、retimer、DSP 和硅光布局同时受益。
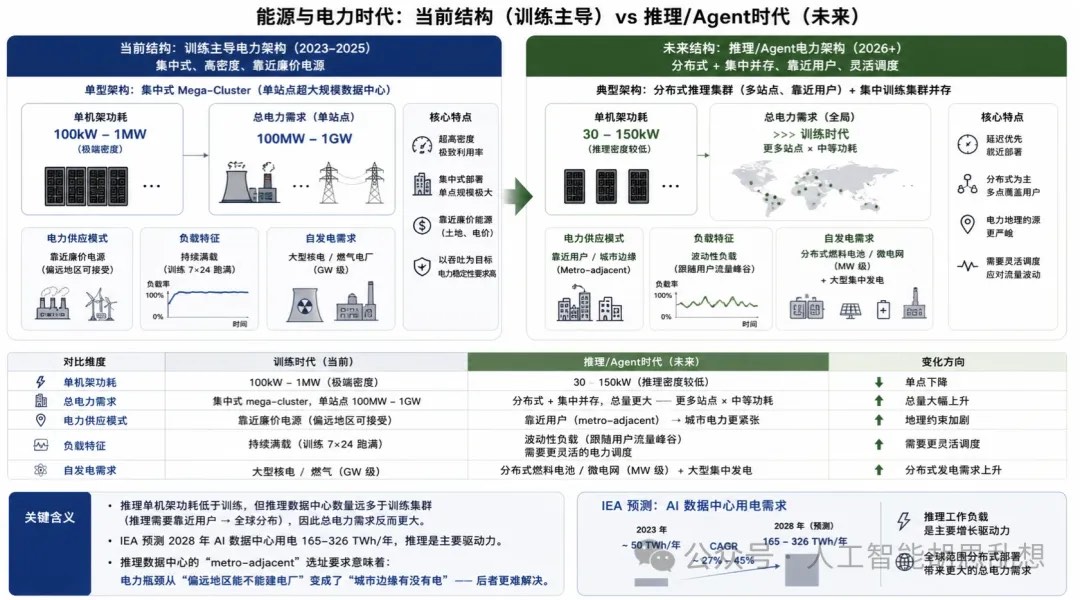
第四层:发电与电力供应
电力供应是 AI 数据中心的物理边界。芯片、服务器和网络设备可以快速迭代,电力扩容不能按同样速度完成。
发电与电力供应
推理单机架功耗可能低于最大训练机架,但推理站点数量更多、部署更接近用户、运行时间更持续。总电力需求仍会上升。AI 负载从少数超大训练集群扩展到大量推理站点后,电力瓶颈从“有没有偏远地区大电源”变为“城市边缘有没有可用电力容量”。主要供电路径包括电网接入、现场天然气发电、核能 PPA、燃料电池和储能系统。电网接入最传统,但排队和容量不足正在成为项目上线约束。现场发电和燃料电池的价值来自绕开电网瓶颈。核能 PPA 的价值来自 24/7 稳定低碳电力。投资含义。发电层的核心不是单一技术路线,而是“可用、稳定、可快速接入”的电力。Bloom Energy、Constellation Energy、GE Vernova、NextEra 和储能链条都需要进入跟踪池。最终胜出者取决于项目交付周期、单位电力成本、客户 PPA 能力和监管路径。
第五层:电力输配与管理
电力输配层负责把电从电网或现场电源送到机架。随着机架功耗从几十千瓦上升到数百千瓦,供配电系统从传统工程配套升级为 AI 数据中心核心设备链。
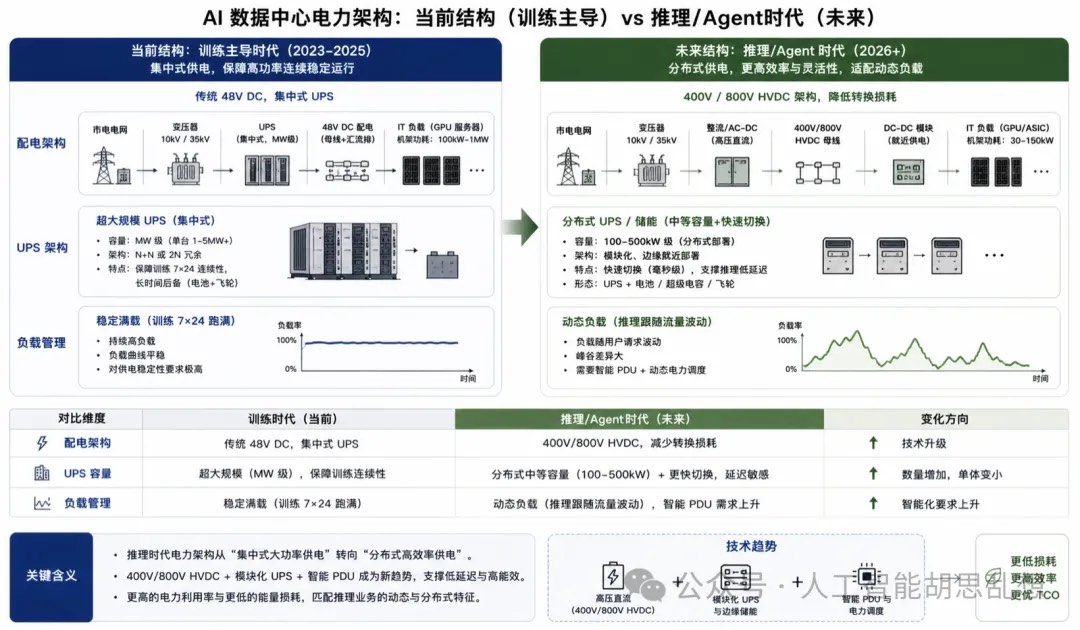
电力输配系统关键设备包括大型变压器、UPS、PDU、母排、开关柜、HVDC、电源模块和电力半导体。大型变压器交期可达数年,是新增项目的隐性约束。UPS 和 PDU 的规格升级来自更高机架功率、更高冗余要求和更复杂的实时监控。800V HVDC、垂直供电和宽禁带半导体是结构性升级方向。更高电压架构减少转换损耗和铜用量,支持更高电流密度。电力半导体从传统服务器电源扩展到 GPU、ASIC、机架和设施级供电系统。投资含义。供配电是 AI 数据中心资本开支中确定性较高的环节。Vertiv、Eaton、Schneider Electric、ABB 和 Delta Electronics 分别受益于电力设备、UPS、配电、变压器、电源模块和系统集成。Vertiv 的弹性来自电力与冷却一体化;Eaton 的价值来自电力管理与热管理能力合并。
第六层:冷却
冷却层正在从辅助系统变成核心交付条件。传统风冷难以支持 100kW 以上高密度机架,液冷成为高端 AI 机架的基础配置。
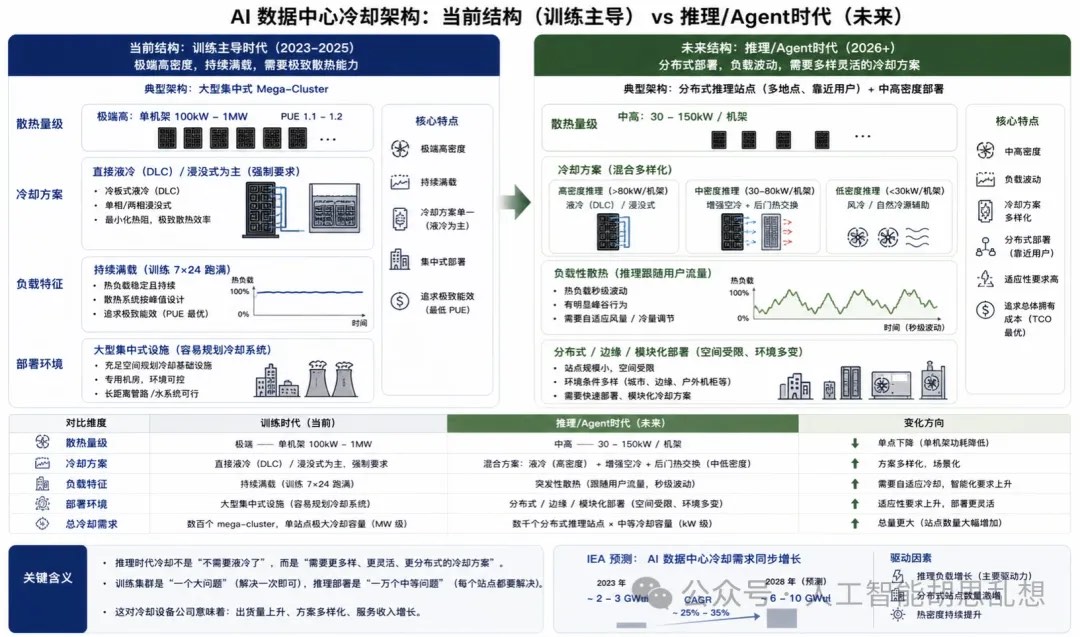
直接液冷把冷板贴近芯片,适用于 GPU、ASIC 和高功耗 CPU。浸没式冷却适用于极端密度场景,但部署和运维复杂度更高。CDU、热交换器、冷却塔、后门热交换器和管路系统共同决定液冷数据中心的工程可行性。液冷的投资价值来自渗透率跃迁。它不是线性增长的配套市场,而是从“可选配置”变成“高密度 AI 数据中心必选条件”。该变化会提高设备单 MW 价值量,并推动认证供应商获得溢价。投资含义。 Vertiv、nVent、Asetek、CoolIT、GRC 和 Eaton/Boyd 是主要跟踪对象。中小型液冷公司更接近“下一个闪迪”的候选特征:初始市场小、渗透率陡升、客户认证门槛高、供给扩张需要工程能力。
第七层:先进封装与基板
先进封装把芯片设计转化为可交付产品。AI 芯片的性能不再只由晶体管决定,GPU、ASIC、HBM、基板、封装和测试共同决定系统上限。
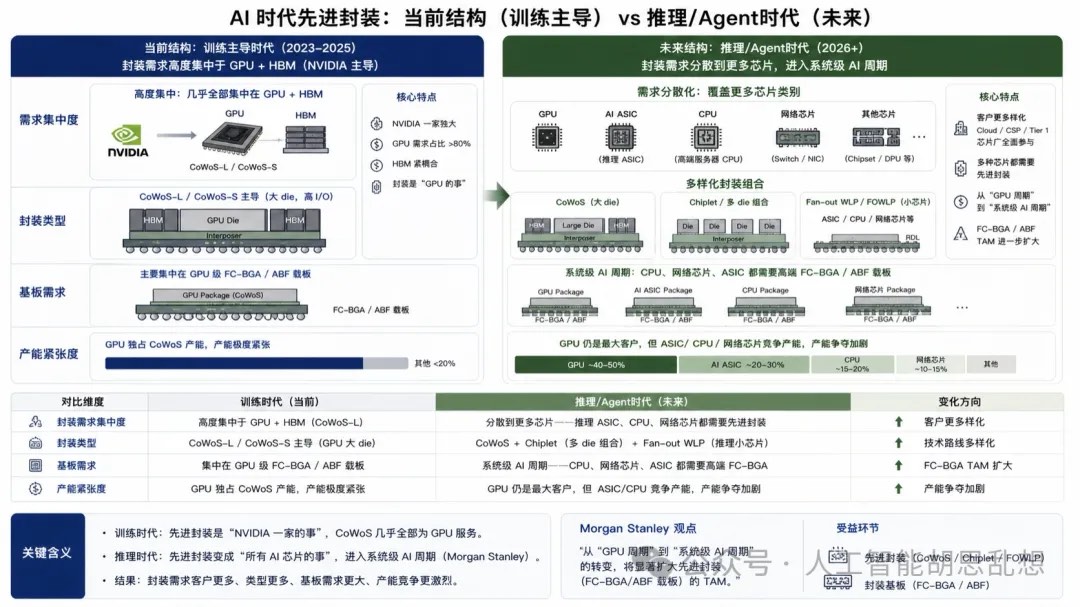
CoWoS 是 GPU 与 HBM 集成的关键能力。ABF 与 FC-BGA 载板决定高端芯片封装密度和信号完整性。高端 PCB、CCL 和连接器则把系统从板卡级升级到机柜级。封装瓶颈具有长周期属性。产能扩张需要设备、材料、良率、客户验证和封装路线共同成熟。相比芯片设计公司,载板和封装供应商的估值往往较低,但单位系统价值量随 AI 机架复杂度持续上升。Intel EMIB、TSMC CoWoS、CoWoS-L、CoWoS-S 和高端 OSAT 产能构成未来竞争焦点。美国在岸化需求也会提高非台系先进封装方案的重要性,但大规模替代需要时间验证。投资含义。 TSMC、ASE、Unimicron、Kinsus、Ibiden、Shinko 和关键测试供应商需要作为一组跟踪。载板/PCB 是容易被低估的盈利放大器。系统复杂度越高,单机价值量越大;客户验证越严格,供给越难快速扩张。
第八层:土地、房地产与建设
数据中心开发的核心资产正在从土地面积转向“带电土地”。能快速接入电力、光纤和冷却资源的地块,正在获得基础设施稀缺溢价。
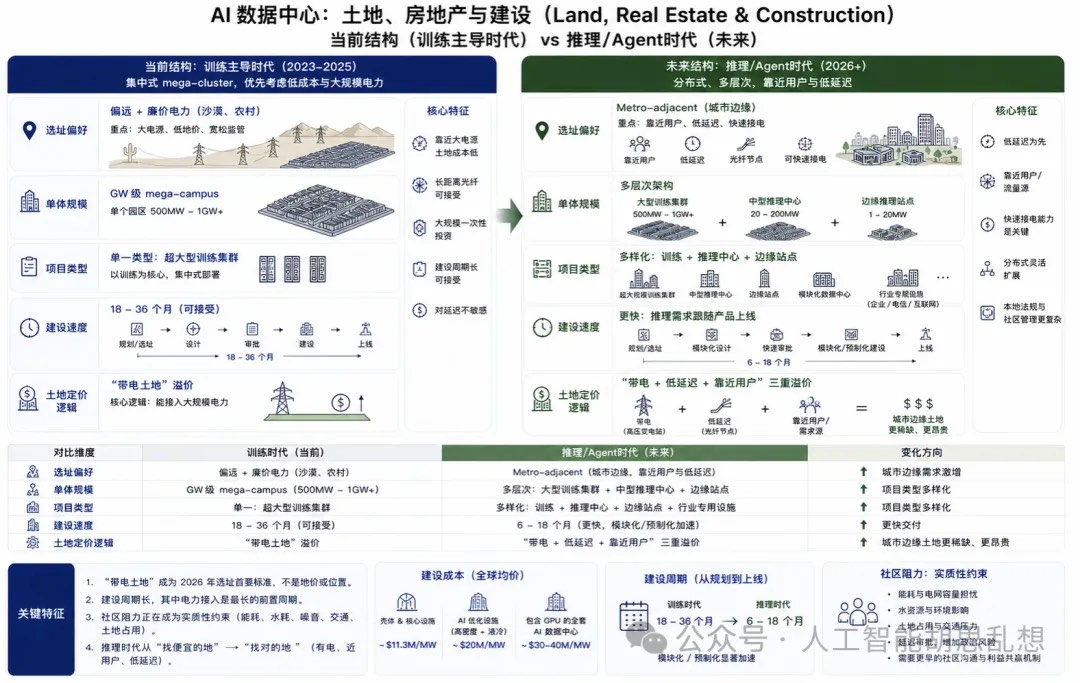
AI 数据中心建设成本显著高于传统数据中心。壳体和核心设施成本通常按每 MW 衡量;高密度液冷、电力冗余和完整 GPU 系统会进一步推高单位 MW 投资额。项目从规划到上线通常需要 18-36 个月,电力接入、审批和社区接受度是主要不确定项。BTC 矿场转型 AI 数据中心的逻辑来自存量电力和土地。矿场资产原本用于低价值挖矿负载,一旦转换为 AI 推理或高性能计算承载能力,单位电力价值可能上升。该路径的关键验证点是客户合同、改造成本、并网条件和融资能力。投资含义。 Equinix、Digital Realty、Core Scientific、IREN、Cipher Mining 和大型私募基础设施平台需要纳入地产与带电土地框架。Core Scientific 等转型公司具备高弹性,但同时承担客户集中、建设执行、融资和电价风险。
第九层:能源基础设施
能源基础设施比发电更上游。它决定电力能否从发电端跨区域输送到数据中心,并以可承受的成本完成接入。
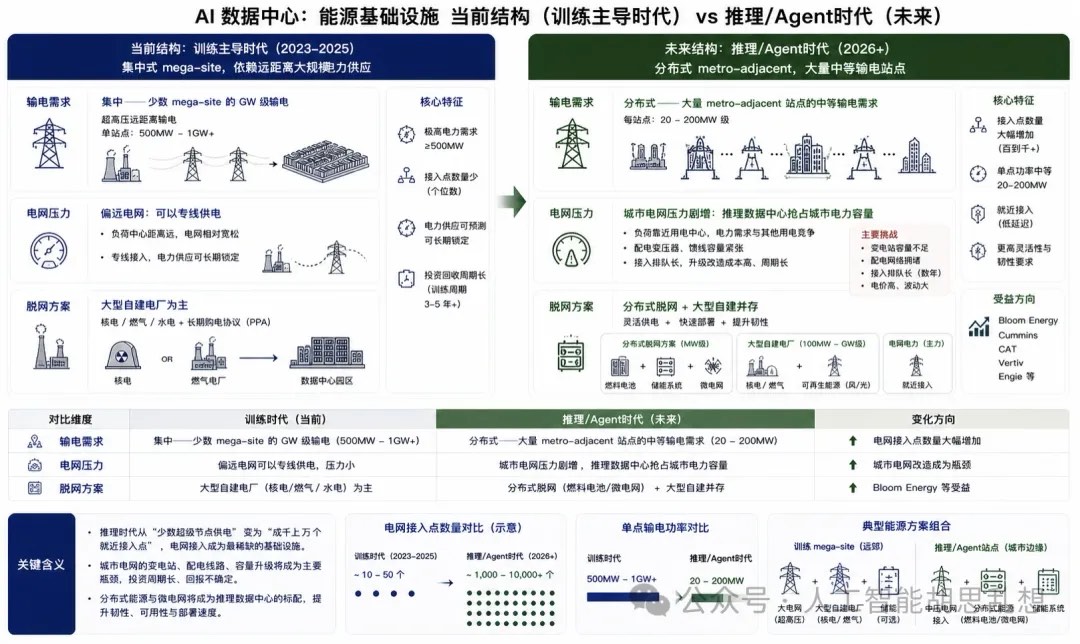
能源基础设施包括输电线路、变电站、电网互连、PPA、现场发电、微电网和储能系统。该层扩张周期最长。输电线路和大型变电站通常需要多年规划、审批和施工;核电重启或新建周期更长。AI 数据中心需求以指数级方式扩张,能源基础设施以线性方式扩张。时间错配决定稀缺性。即使芯片供给改善,电力接入不足仍会推迟项目上线。
约束项典型周期对数据中心的影响大型变压器 2-3 年决定接入和扩容速度变电站 2-5 年决定区域可用容量输电线路 5-10 年决定跨区域电力配置核电重启/新建多年到十年以上决定长期 24/7 低碳电力供给PPA 与互连审批数月至数年决定项目融资和上线时间投资含义。能源基础设施是“下一个闪迪”概率最高的区域之一。它同时具备需求爆发、供给刚性、审批瓶颈和市场再定价条件。Bloom Energy、Constellation Energy、GE Vernova、Quanta Services、公用事业和部分矿场转型公司都应纳入跟踪。
第十层:设施系统与运维
设施系统把计算、电力、冷却、网络和安全系统整合为可运营资产。该层本身不是最紧瓶颈,但在推理时代的软件价值会上升。

推理时代的数据中心更分布、更动态。数千个液冷机架、跨站点负载调度和实时功耗管理提高 DCIM 和自动化运维的重要性。设施系统从硬件配套升级为实时监控、容量管理、能耗优化和风险控制平台。
维度训练时代推理与 Agent 时代变化机架设计少数高密度定制机架高密度液冷、中密度标准、边缘微型并存 SKU 增加DCIM 单集群监控为主分布式容量、功耗和冷却调度软件价值上升运维人工巡检可支撑 AIOps 与自动化响应自动化率提高安全传统物理安全算力资产、模型资产和数据资产共同防护安全边界扩大投资含义。设施系统主要贡献给 Vertiv、Schneider Electric、nVent、Rittal、Nlyte 和 Sunbird 等公司。独立机会更多来自 DCIM、液冷监控、功耗优化和 AI 运维软件。
供需状态与投资排序
十层架构的供需状态差异明显。GPU 高端代际仍紧,但市场认知充分;电力、土地、封装、冷却、网络和存储的部分子环节仍存在认知差。
层级供需状态投资优先关键验证指标级能源基础结构性短缺高 PPA、互连排队、变电站和输电项目设施电力输配结构性紧张高变压器交期、UPS 订单、HVDC 采用冷却渗透率跃迁高液冷认证客户、CDU 产能、单 M W 价值量
内存与存 HBM 与 SSD 双重紧张高 HBM 供给、 NAND 价格、 数据中储心 SSD 出货网络与互 800G/1.6T 迁移中高光模块缺口、AEC 放量、CPO 节奏连封装与基长周期瓶颈中高 CoWoS、ABF、FC-BGA 扩产和良板率计算 GPU 充分认知,CPU/ASIC 有中 CPU 供需、ASIC 客户扩张、GPU 代边际变化际交付土地与建带电土地稀缺中客户合同、并网、电力容量、改造成设本设施系统软件化升级中低 DCIM 渗透率、液冷监控和自动化运维
下一篇报告将重点研究
推理、MoE、多模态、Agent 和边缘/混合部署对数据中心的影响。每一项力量都会改变不同层级的需求弹性。推理提升 CPU、SSD、网络和电力价值;MoE 改变内存带宽和通信模式;多模态提高算力、存储和网络压力;Agent 提高控制面和长期记忆需求;边缘/混合部署提高分布式数据中心和 DCI 需求。
最后将在公司层面进行筛选
方法与资料口径
本文使用公司公告、公开演示材料、行业研究、公开数据源和已整理的研究素材。涉及未来年份的收入、容量、功耗、市场规模和供需缺口均为估算值,需随公司披露、供应链订单、资本开支指引和电力项目进展持续更新。本文不构成投资建议。上市公司估值、股价表现、目标价和持仓数据会随市场变化而变化,正式投资排序需要使用同一日期的市场数据重新核验。